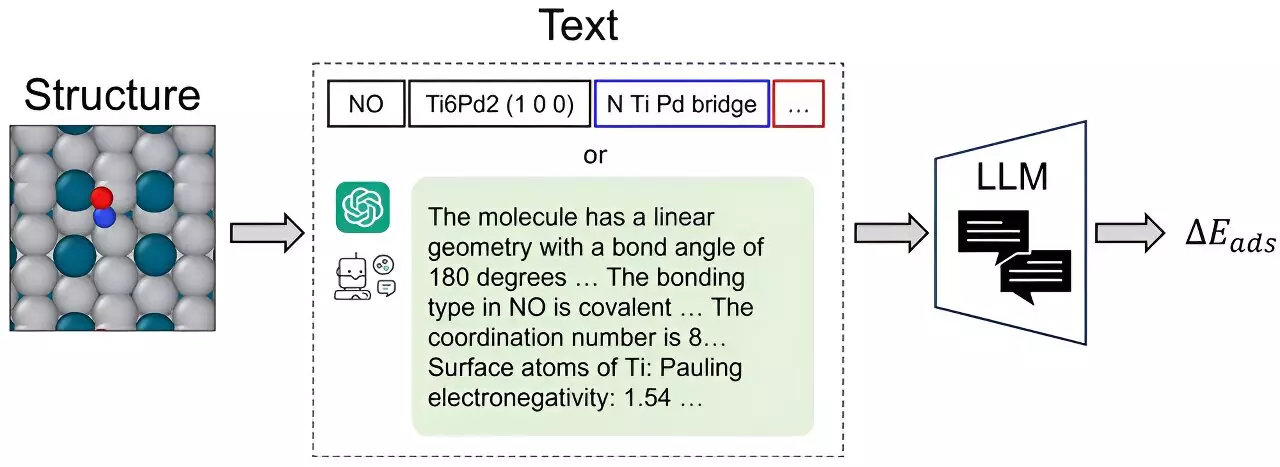
Catalysts play a vital role in various industrial processes, ranging from the production of everyday items like yogurt and Post-It notes to the development of renewable energy sources. However, finding the optimal catalyst materials for specific reactions has traditionally been a challenging and time-consuming task. Scientists often rely on laborious experiments and computationally intensive calculations to identify suitable catalysts. To address this issue, researchers at Carnegie Mellon University’s College of Engineering have developed CatBERTa, an energy prediction Transformer model that leverages machine learning techniques to streamline the process of catalyst discovery.
Unlike previous methods, CatBERTa utilizes a large language model (LLM) to predict the properties of an adsorbate-catalyst system without the need for preprocessing the input text. This unique feature makes the model easily interpretable by humans, enabling researchers to seamlessly integrate observable features into their data analysis. By applying the transformer model, the researchers gain valuable insights into the structural intricacies of atomic systems. The self-attention scores, in particular, enhance their understanding of interpretability within this framework, further improving their comprehension of catalyst behavior.
One notable achievement of CatBERTa is its comparable predictive accuracy to earlier versions of graph neural networks (GNNs). Surprisingly, the model demonstrated greater success when trained on limited-size data sets. Additionally, it outperformed existing GNNs in terms of error cancellation abilities. While the researchers acknowledge that CatBERTa might not replace state-of-the-art GNNs, they view it as a complementary approach to catalyst screening. Embracing the motto “The more, the merrier,” they believe that combining multiple techniques can provide a more comprehensive understanding of catalyst performance.
The focus of the team’s research has primarily been on adsorption energy. However, they emphasize that the CatBERTa approach can be extended to other properties, such as the HOMO-LUMO gap and stabilities related to adsorbate-catalyst systems, given an appropriate dataset. The integration of extensive language models with the demands of catalyst discovery holds immense potential for streamlining the screening process. By reducing the reliance on traditional experimental methods and time-consuming calculations, researchers can expedite the identification of effective catalyst materials.
Janghoon Ock, a Ph.D. candidate in Amir Barati Farimani’s lab, is currently dedicated to further enhancing the accuracy of the CatBERTa model. As with any innovative technology, there is always room for improvement. By optimizing the model’s performance, Ock aims to maximize its predictive capabilities and cement its position as a valuable tool in catalyst discovery.
CatBERTa represents a significant advancement in the field of catalyst discovery. Leveraging the power of machine learning and language processing, this innovative approach offers a streamlined and interpretable solution for predicting the properties of adsorbate-catalyst systems. While it may not replace existing techniques, CatBERTa serves as a complementary tool, enhancing the comprehensiveness of catalyst screening. With ongoing efforts to improve its accuracy, CatBERTa holds tremendous promise for accelerating the development of efficient catalyst materials.
Leave a Reply