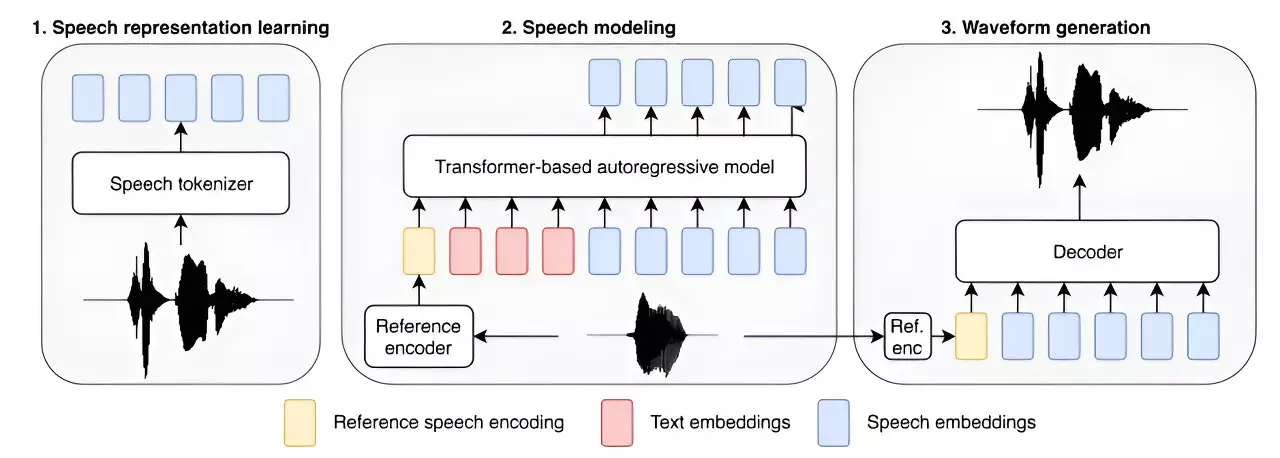
The team of artificial intelligence researchers at Amazon AGI has recently unveiled their groundbreaking achievement in the field of text-to-speech technology. They have successfully developed the largest text-to-speech model to date, boasting an impressive 980 million parameters and trained using a massive dataset of 100,000 hours of recorded speech. This new model, known as Big Adaptive Streamable TTS with Emergent abilities (BASE TTS), represents a significant advancement in the capabilities of AI-powered speech synthesis.
One of the key goals of the researchers was to enhance the linguistic abilities of the text-to-speech application by increasing the number of parameters and expanding its training data. By exposing the model to a wide range of spoken words and phrases in multiple languages, including English, the team aimed to improve its pronunciation accuracy and overall performance. Additionally, the incorporation of examples from different linguistic contexts allowed the model to develop a better understanding of language nuances and expressions.
Through rigorous testing on various data sets, the team at Amazon identified a critical juncture where the text-to-speech model exhibited what is commonly referred to as an emergent quality. This phenomenon, characterized by a sudden breakthrough in the intelligence level of an AI application, was observed when the model reached 150 million parameters. The emergence of advanced linguistic capabilities, such as the use of compound nouns, emotional expression, foreign language integration, and nuanced punctuation, marked a significant milestone in the development of BASE TTS.
Despite the impressive advancements achieved by the researchers, they have decided not to release the BASE TTS model to the public due to concerns about potential unethical usage. Instead, they plan to leverage it as a learning tool to further enhance the natural-sounding quality of text-to-speech applications in the future. By utilizing the insights gained from their research, the team at Amazon aims to push the boundaries of AI technology and continue driving innovation in the field of speech synthesis.
Overall, the development of BASE TTS represents a major step forward in the evolution of text-to-speech technology, demonstrating the immense potential of AI-powered systems to mimic human speech with unprecedented accuracy and intelligence. As researchers continue to explore new possibilities in this rapidly advancing field, we can expect to see even more remarkable innovations that redefine the way we interact with AI-driven applications.
Leave a Reply