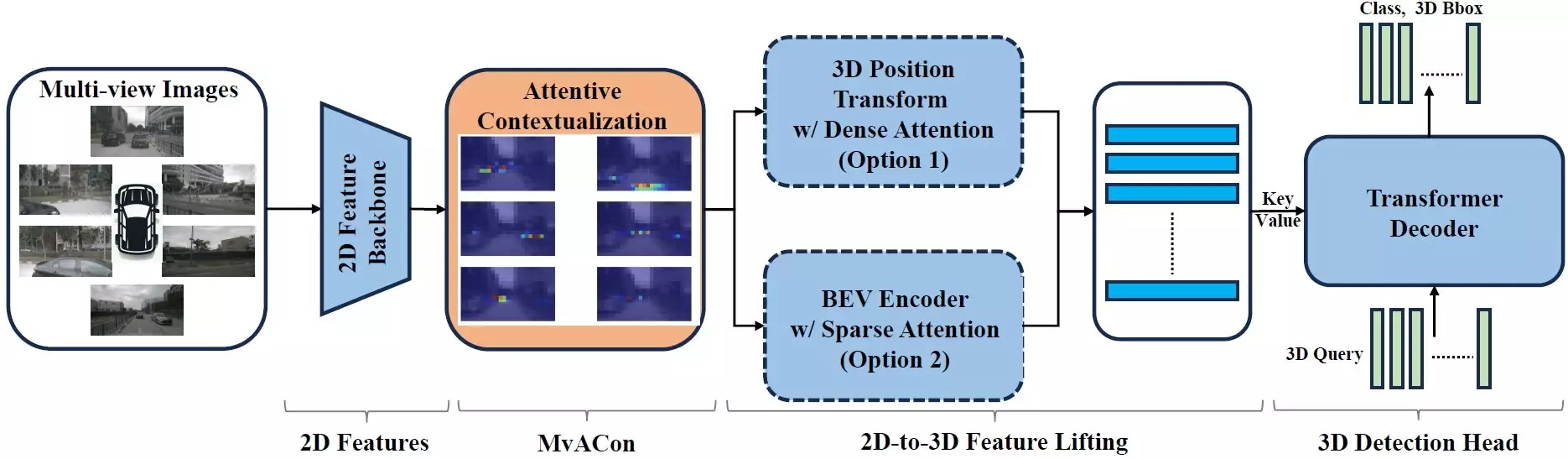
Artificial intelligence programs have reached a new milestone with the development of a groundbreaking technique known as Multi-View Attentive Contextualization (MvACon). This technique allows AI programs, specifically vision transformers used in autonomous vehicles, to effectively map three-dimensional spaces using data collected from two-dimensional images captured by multiple cameras. The research, led by Tianfu Wu, an associate professor of electrical and computer engineering at North Carolina State University, showcases the potential of MvACon to significantly enhance the navigation capabilities of autonomous vehicles.
Traditionally, autonomous vehicles rely on powerful AI programs called vision transformers to process 2D images from various cameras and generate a spatial understanding of the surrounding environment. While these vision transformers are adept at their task, there is always room for improvement. Wu’s team introduced MvACon as a supplementary technique that can be seamlessly integrated with existing vision transformers to enhance their ability to map 3D spaces. By leveraging MvACon, vision transformers can optimize their utilization of data without the need for additional computational resources.
The core functionality of MvACon revolves around the refinement of an existing approach called Patch-to-Cluster attention (PaCa), initially introduced by Wu and his collaborators. PaCa enables transformer AIs to efficiently identify objects within an image. By extending this concept to the challenge of mapping 3D space using data from multiple cameras, MvACon demonstrates a significant leap in performance. Through rigorous testing with three prominent vision transformers – BEVFormer, BEVFormer DFA3D variant, and PETR – MvACon consistently outperformed in improving object detection, object localization, speed, and orientation accuracy.
The successful implementation of MvACon in conjunction with leading vision transformers highlights its potential to revolutionize the field of autonomous vehicle navigation. The minimal increase in computational demand when integrating MvACon further solidifies its viability for widespread adoption. Wu and his team are now focused on expanding the testing of MvACon across diverse benchmark datasets and real-world video inputs from autonomous vehicles. If the results continue to exceed expectations, MvACon could emerge as a prominent solution for enhancing the capabilities of existing vision transformers in various applications.
The research paper titled “Multi-View Attentive Contextualization for Multi-View 3D Object Detection” presents a significant advancement in the realm of artificial intelligence and autonomous vehicle technology. Spearheaded by Xianpeng Liu, the study brings together a collaborative effort from researchers at various institutions, underscoring the interdisciplinary nature of innovation in this field. The upcoming presentation of this research at the IEEE/CVF Conference on Computer Vision and Pattern Recognition signifies its importance and relevance in the scientific community. As MvACon continues to shape the landscape of AI-powered navigation systems, the future holds immense possibilities for further advancements in mapping 3D spaces with unparalleled precision and efficiency.
Leave a Reply