Companies that develop large language models face the challenge of ensuring the safety and integrity of their AI systems. Traditional red-teaming techniques involve human testers generating prompts to test the responses of the models, but this manual process is both time-consuming and limited in its effectiveness. Researchers from Improbable AI Lab at MIT and the MIT-IBM Watson AI Lab have proposed a new approach that leverages machine learning to enhance red-teaming efforts.
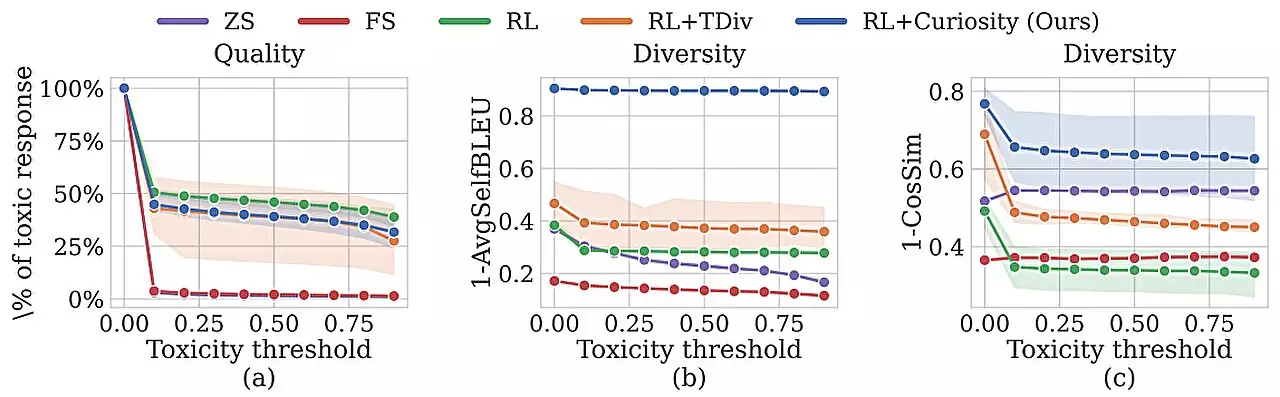
The research team developed a technique that trains a red-team model to automatically generate diverse prompts that elicit a wide range of responses from the chatbot being tested. By incorporating curiosity-driven exploration into the training process, the red-team model is encouraged to focus on novel prompts that provoke toxic responses from the target model. This approach outperformed traditional human testers and other machine-learning methods by generating more diverse prompts that elicited increasingly toxic reactions.
Novelty Rewards and Safety Measures
To prevent the red-team model from producing random or nonsensical prompts, the researchers included novel reward mechanisms in the reinforcement learning setup. These rewards incentivize the model to explore different word choices, sentence structures, and meanings in its prompts. By incorporating entropy bonuses and naturalistic language constraints, the red-team model is guided to generate meaningful prompts that effectively test the chatbot’s responses.
Scalability and Efficiency
The traditional manual red-teaming process is not conducive to the rapid evolution of AI models in dynamic environments. The researchers’ method offers a faster, more efficient way to conduct quality assurance testing on large language models. As the AI landscape continues to expand with the introduction of new models and frequent updates, automated red-teaming becomes crucial to ensure the safety and reliability of these systems.
Looking ahead, the researchers aim to enhance the red-team model’s ability to generate prompts across a wider range of topics. They also plan to explore the use of a large language model as a toxicity classifier, enabling users to train the classifier based on specific criteria such as company policies. This approach would allow red-teaming to test AI models for compliance with industry standards and regulations, further enhancing the trustworthiness of these systems.
The integration of machine learning techniques such as curiosity-driven exploration in red-teaming processes represents a significant advancement in ensuring the safety and reliability of AI models. By automating the generation of diverse and challenging prompts, researchers can more effectively assess the responses of large language models and identify potential vulnerabilities. As AI continues to play a prominent role in various industries, approaches like curiosity-driven red-teaming will be essential in building a safer and more trustworthy AI future.
Leave a Reply