Large language models (LLMs) have gained popularity due to their ability to process, generate, and manipulate texts in various human languages. These models are increasingly being utilized in different settings to find answers to queries, produce content, and interpret complex texts. However, researchers have noted that LLMs are prone to generating hallucinations, which are responses that are incoherent, inaccurate, or inappropriate.
A team of researchers at DeepMind developed a novel approach to address the issue of hallucinations in LLMs. The proposed method involves the LLM evaluating its own responses to determine their similarity and confidence level. This self-evaluation technique aims to identify instances where the model should abstain from answering a query to prevent hallucinations.
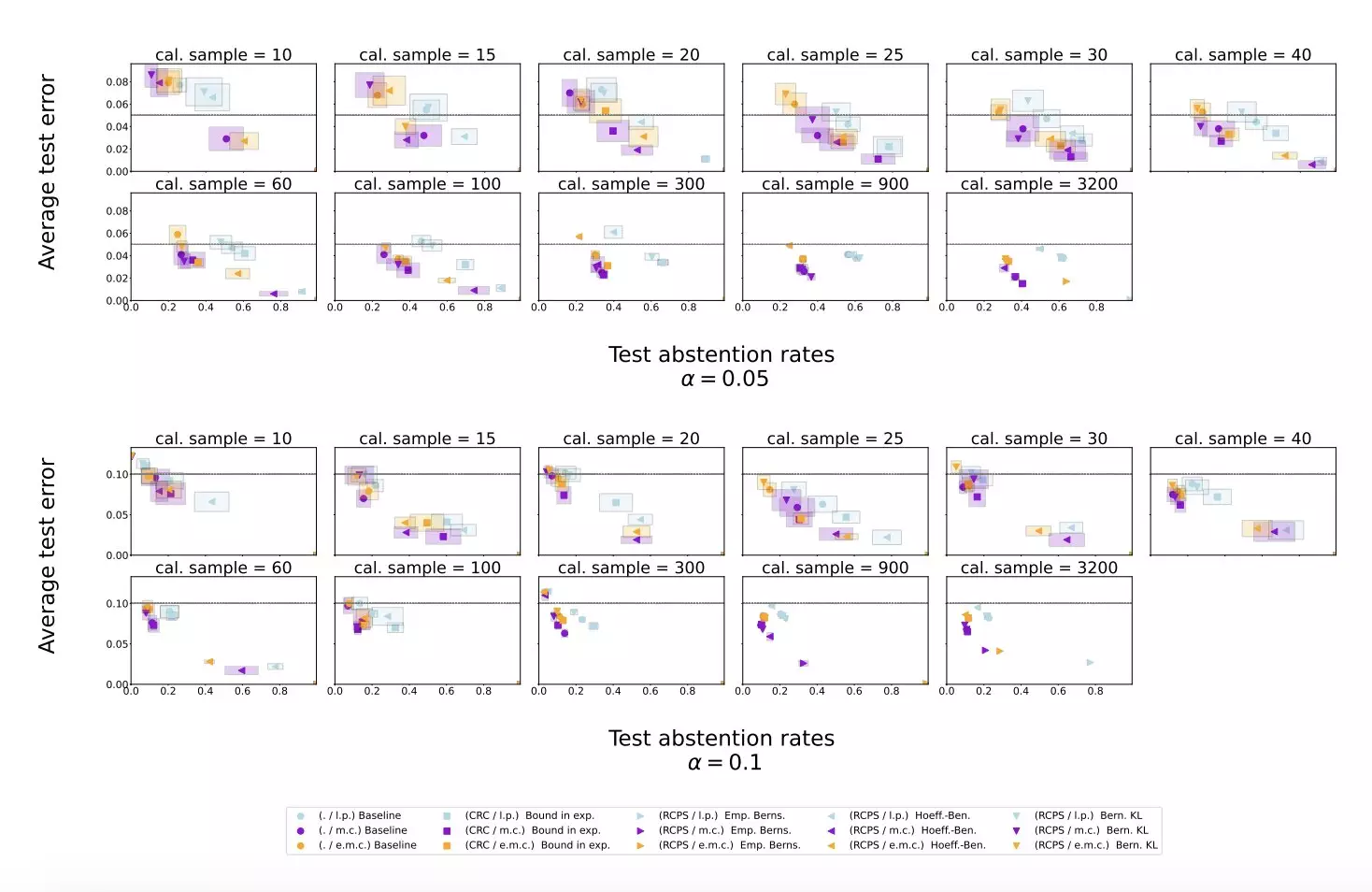
The researchers conducted experiments using publicly available datasets, Temporal Sequences and TriviaQA, to evaluate the effectiveness of their proposed method. They applied the approach to Gemini Pro, an LLM developed by Google, and found that the conformal abstention method reliably reduced the hallucination rate while maintaining a reasonable abstention rate.
The results of the experiments conducted by the research team suggest that the proposed calibration and similarity scoring procedure can effectively mitigate hallucinations in LLMs. This approach outperformed simple baseline scoring procedures and could inform the development of similar methods to enhance the reliability of LLMs in the future.
Addressing hallucinations in large language models is crucial to ensure the accuracy and reliability of their responses. The proposed approach by DeepMind demonstrates a promising method to mitigate hallucinations in LLMs, paving the way for the advancement of these models in various applications. By preventing hallucinations, LLMs can be used more effectively in professional settings, contributing to their widespread adoption and use worldwide.
Leave a Reply