Large language models (LLMs) have revolutionized the way we interact with conversational platforms like ChatGPT. The groundbreaking GPT-4 model has managed to astound users with its ability to not only comprehend written prompts but also generate responses in various languages. This leads to the burning question: are these AI-generated texts and answers so realistic that they could easily pass off as human-generated? Researchers at UC San Diego tackled this query by conducting a Turing test, a method devised by Alan Turing to gauge human-like intelligence shown by machines. The intriguing findings of this experiment have been detailed in a paper pre-published on the arXiv server, shedding light on the remarkable capabilities of these advanced AI models.
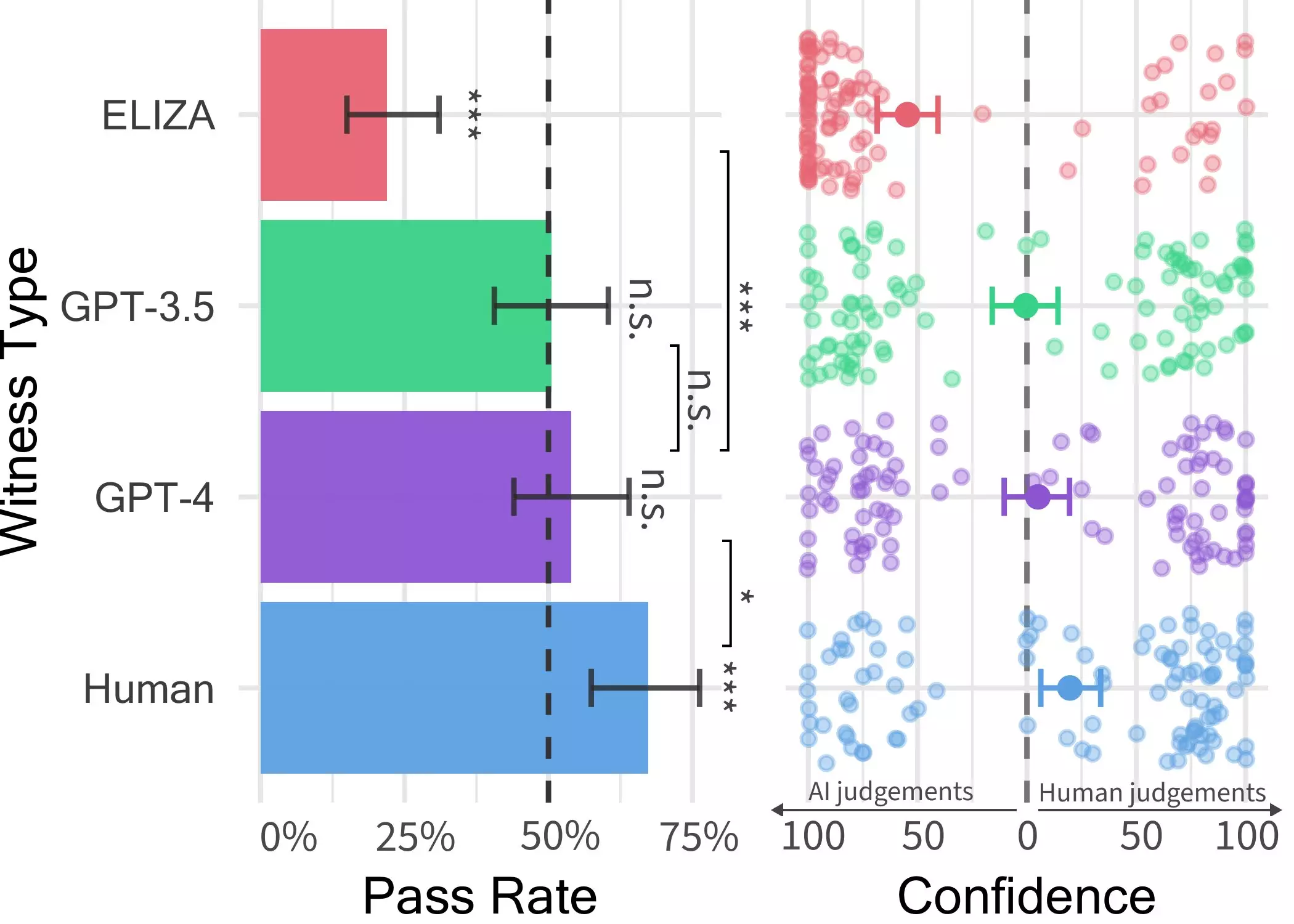
The initial study conducted by Cameron Jones and supervised by Prof. Bergen revealed that GPT-4 could convincingly impersonate a human in around 50% of the interactions. However, the researchers noted certain variables that were not adequately controlled for in this exploratory experiment. To address this gap, a second experiment was conducted, with its results featured in their recent paper. Throughout this process, Jones and his team stumbled upon similar work being done in this field by others, such as Jannai et al’s ‘human or not’ game, prompting them to develop their own two-player online version of the game for further investigation.
Testing the Human-AI Distinction
During each trial of the two-player game devised by Jones, a human interrogator engages with a “witness” who could be a fellow human or an AI agent. The interrogator poses a series of questions to determine the authenticity of the witness. The dynamic conversations span up to five minutes, following which the interrogator must decide if the witness is human or an AI. While conversations could revolve around any topic, the participants were prohibited from making abusive remarks, enforced by a filtering system. The study saw the deployment of three distinct LLMs as potential witnesses – GPT-4, GPT 3.5, and ELIZA, with varying outcomes in each case.
Jones and Bergen’s findings from the Turing test underscore the remarkable fact that LLMs, especially GPT-4, can closely mimic human interactions during brief chat sessions. This blurring of lines between AI and humans could potentially lead to a rise in skepticism among online users, unsure whether they are engaging with real individuals or sophisticated bots. The implications of these results are far-reaching, hinting at potential misuses where AI systems could be leveraged for deception, fraud, or misinformation. This raises critical questions on the future applications of AI, especially in client-facing roles or scenarios involving sensitive information.
The research team is now contemplating updating and reopening the public Turing test to explore additional hypotheses and gather more insights. An intriguing idea that Jones mentions is running a three-person iteration of the game, where an interrogator interacts simultaneously with a human and an AI system, challenging them to discern between the two. This future avenue of exploration could reveal deeper layers of understanding on the human-AI dynamics, further blurring the boundaries between man and machine.
Leave a Reply