In the realm of robotics, the ability for robots to effectively grasp and manipulate objects in real-world environments is a critical aspect. Over the years, developers have turned to machine learning models to enhance object manipulation capabilities in robots. While some of these models have shown promise, they often require extensive pre-training on large datasets to perform well. These datasets typically consist of visual data, such as annotated images and video footage, with some approaches incorporating other sensory inputs like tactile information.
A recent study conducted by researchers at Carnegie Mellon University and Olin College of Engineering delved into the potential of using contact microphones as an alternative to traditional tactile sensors. By leveraging audio data, the researchers aimed to pre-train machine learning models for robot manipulation on a larger scale than what is currently done. This innovative approach could pave the way for enhanced multi-sensory pre-training in robotics applications.
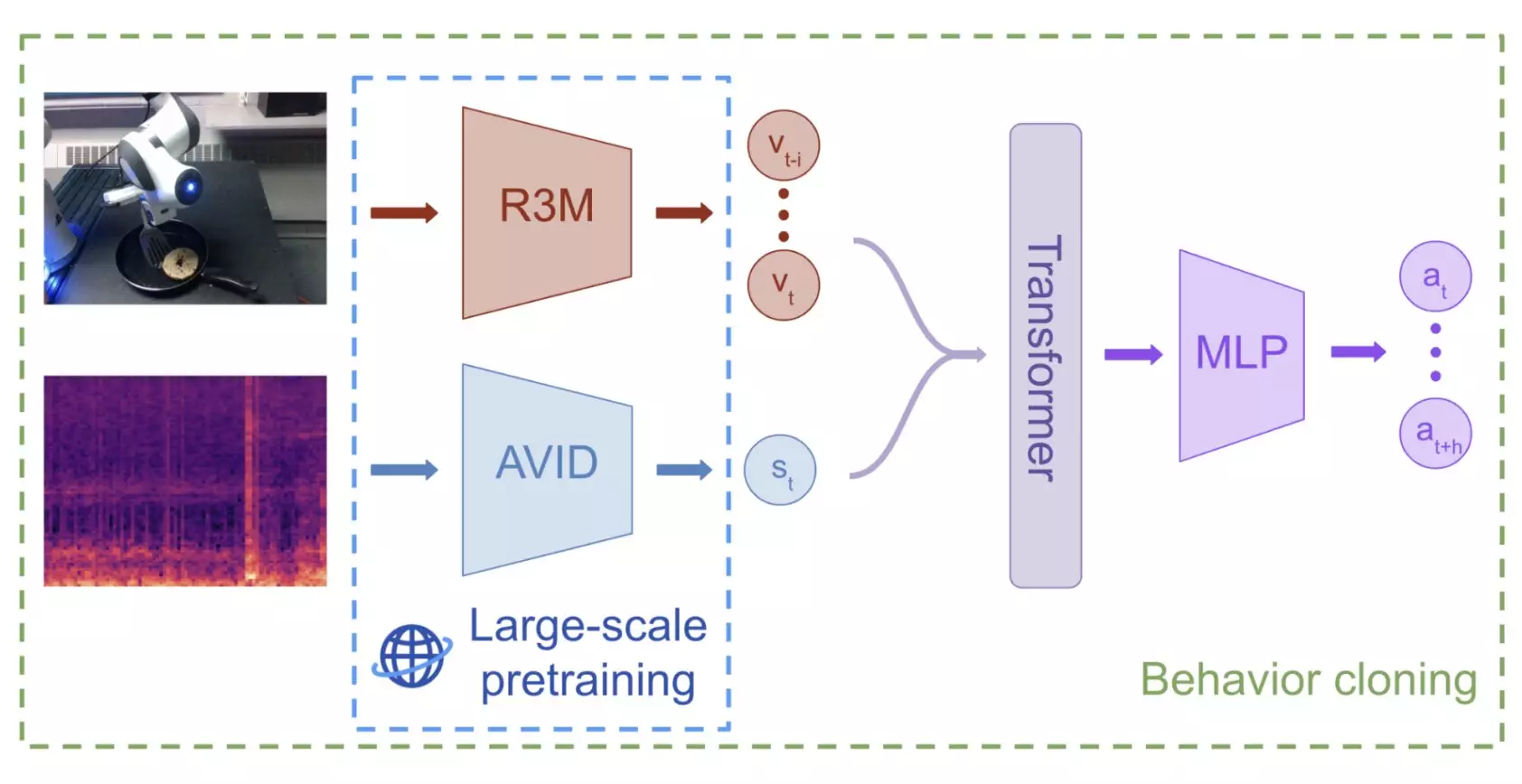
The team of researchers, led by Jared Mejia and Victoria Dean, employed a self-supervised machine learning method to pre-train their model on audio-visual representations from the Audioset dataset. This dataset comprises over 2 million 10-second video clips of sounds and music gathered from the internet. The model utilized audio-visual instance discrimination (AVID) to learn to differentiate between various audio-visual data types.
To assess the effectiveness of their approach, Mejia, Dean, and their collaborators put the model to the test in a series of real-world manipulation tasks. The robot was provided a maximum of 60 demonstrations for each task, and the results were highly promising. The pre-trained model surpassed policies that rely solely on visual data, especially when faced with objects and scenarios not present in the training data. This breakthrough highlights the potential of leveraging audio-visual pretraining for improved robotic manipulation.
Moving forward, the study conducted by Mejia, Dean, and their team could mark a significant advancement in the field of robot manipulation. By utilizing pre-trained multimodal machine learning models, the possibilities for skilled robotic manipulation are endless. Future research may focus on refining and expanding this approach to a broader range of manipulation tasks in real-world settings. The team’s work sets the stage for further exploration into the optimal properties of pre-training datasets for learning audio-visual representations in manipulation policies.
The integration of contact microphones and audio data into the pre-training of machine learning models for robot manipulation shows great promise. By harnessing the power of multi-sensory learning, researchers are paving the way for more sophisticated and versatile robots that can excel in a variety of tasks. The future of robot manipulation lies in the fusion of different modalities and the constant innovation of machine learning techniques.
Leave a Reply